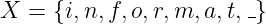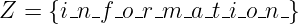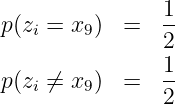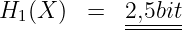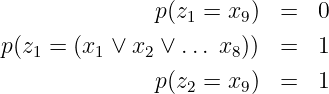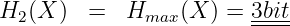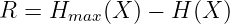Eine diskrete gedächtnislose Quelle X erzeugt in jedem Zeittakt T ein Zeichen xi aus dem Alphabet X = {x1,x2,…,xN} mit der Wahrscheinlichkeit P(xi) = pi.
→Gedächtnislos heisst, das aktuelle Zeichen ist unabhängig von den bereits erzeugten.
Die Definition des Informationsgehalts eines Zeichens ist
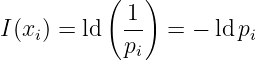 | (6.2.1) |
mit folgenden Eigenschaften:
- Der Informationsgehalt ist ein nicht negatives Maß
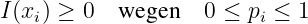
(6.2.2) - Für ein Zeichen mit pi = 1∕2 ist der Informationsgehalt I(xi) = 1. Dies ist die Pseudoeinheit der Information. Sie wird als bit (binary indissoluble information) bezeichnet6
- Ein seltenes Symbol hat einen größeren Informationsgehalt als ein
häufiges Symbol (der Informationsgehalt ist eine stetige Funktion
der Wahrscheinlichkeit)
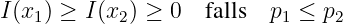
(6.2.3) - Für unabhängige Zeichenpaare (xi,xj) mit der
Verbundwahrscheinlichkeit p(xi ∧ xj) = pi ⋅ pj gilt
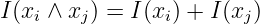
(6.2.6)
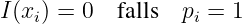
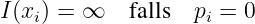
Die Entropie einer Quelle wird (in Anlehnung an die Thermodynamik) als mittlerer Informationsgehalt ihrer Zeichen definiert zu
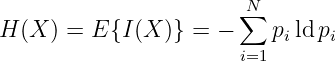 | (6.2.7) |
mit der Einheit bit.
→ Die Entropie ist ein Maß für die Ungewissheit der Zeichen X der Quelle. Das Chaos hat die maximale Entropie!
- Die Entropie wird maximal (gleich dem Entscheidungsgehalt
des Alphabets), wenn alle N Zeichen des Alphabets
gleichwahrscheinlich sind
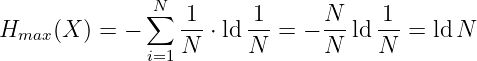
(6.2.8) → Bei binären Quellen mit N verschiedenen Zeichen (für die ld N eine ganze Zahl ist) ist ld N gerade die Anzahl der Binärstellen, um die Zeichen unabhängig von deren Auftrittswahrscheinlichkeit zu kodieren.