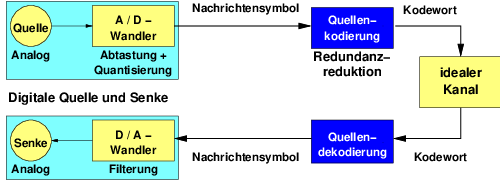
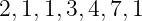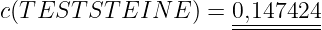Das Ziel einer Quellenkodierung wie in Abb. 7.1.1 ist die zu übertragenden Nachrichtensymbole möglichst optimal in eine Folge von Zeichen zu kodieren.1
→ Verlustfreie Datenkompression mit Reduzierung der Redundanz erfolgt ohne Informationsverlust.
→ Verlustbehaftete Datenkompression mit Reduzierung der Irrelevanz (nicht benötigter Teil der Information) ergibt Informationsverlust.
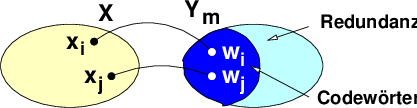
Als Kodierung (siehe auch Abb. 7.1.2) bezeichnet man eine injektive Abbildung, die jedem Zeichen x einer Quelle X ein Kodewort c zuordnet2
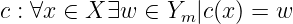 | (7.1.1) |
→ Injektiv: Aus c(x1) = c(x2) folgt x1 = x2.
Y = {y1,…yr} ist dabei ein weiteres Alphabet und w ∈ Y Y … = Y i ein Wort des Alphabets mit der Menge aller Worte
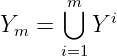 | (7.1.2) |
Die mittlere Wortlänge einer Kodierung kann aus der einzelnen Länge der Kodewörter l(wi) = li bestimmt werden zu
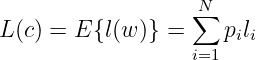 | (7.1.3) |
Das Shannon’sche Kodierungstheorem besagt, dass die mittlere Wortlänge einer Kodierung größer oder bestenfalls gleich der maximalen Entropie der Quelle ist
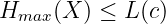 | (7.1.4) |
Mit der Effizienz eines Kodes c für die Quelle X
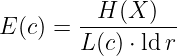 | (7.1.5) |
wird die Redundanz R = L(c) ld(r) − H(X) der Kodierung c erfaßt3, wobei L(c) ld(r) die maximale Entropie des Kodes mit r Buchstaben ist.
Da bei decodierbaren Kodes die gesammte Quelleninformation erhalten bleibt, gibt es einen optimalen oder idealen Kode mit der Effizienz E(c) = 1.
→ Es gibt keinen anderen Kode mit demselben Kodealphabet, der für dieselbe Quelle eine kleinere mittlere Kodelänge aufweist.
- Beispiel: 7 Bit ASCII-Kode
N = 27 = 128 Zeichen → L(c) = 7
Kodierung mit r = 2 Zeichen 0, 1 → ld r = ld 2 = 1.
Quellenentropie
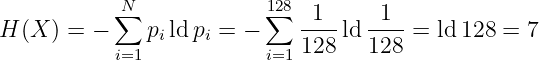
Effizienz des Kodes
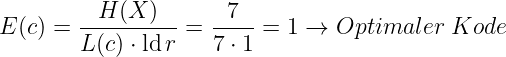
- Voraussetzung: Gleiche Wahrscheinlichkeit pi = 1∕128
Der bekannteste Kode ist das Morsealphabet, das international genormte Telegraphenalphabet4. Benannt nach dem Erfinder Samuel Morse (1791 – 1872), der 1838 das Morsealphabet entwickelte für den von ihm 1 Jahr zuvor konstruierten elektromagnetischen Schreibtelegraphen.
Die Länge der Kodes aus Punkten („di“), Strichen („dat“ = 3 „dit“) korreliert mit der Häufigkeit der Buchstaben in der englischen Schriftsprache (siehe auch Tab. 7.1). Als zusätzliche Trennzeichen ist noch die Pause notwendig: einfach zwischen Zeichen (Länge = „dit“), 3-fach zwischen Kodeworten und 6-fach zwischen Worten des Eingangsalphabets.
| E | - | 16,93 | 12,60 | T | — | 5,79 | 9,37 | ||||||
| I | - | - | 8,02 | 6,71 | M | — | — | 2,55 | 2,53 | ||||
| A | - | — | 5,58 | 8,34 | N | — | - | 10.53 | 6,80 | ||||
| S | - | - | - | 6,42 | 6,11 | O | — | — | — | 2,24 | 7,70 | ||
| U | - | - | — | 3,83 | 2,85 | G | — | — | - | 3,02 | 1,92 | ||
| R | - | — | - | 6,89 | 5,68 | K | — | - | — | 1,32 | 0,87 | ||
| W | - | — | — | 1,78 | 2,34 | D | — | - | - | 4,98 | 4,14 | ||
| H | - | - | - | - | 4,98 | 6,11 | CH | — | — | — | — | ||
| V | - | - | - | — | 0,84 | 1,06 | Ö | — | — | — | - | 0,30 | |
| F | - | - | — | - | 1,49 | 2,03 | Q | — | — | - | — | 0,02 | 0,02 |
| Ü | - | - | — | — | 0,65 | Z | — | — | - | - | 1,21 | 0,06 | |
| L | - | — | - | - | 3,60 | 4,24 | Y | — | - | — | — | 0,05 | 2,04 |
| Ä | - | — | - | — | 0,54 | C | — | - | — | - | 3,16 | 2,73 | |
| P | - | — | — | - | 0,67 | 1,66 | X | — | - | - | — | 0,05 | 0,20 |
| J | - | — | — | — | 0,24 | 0,23 | B | — | - | - | - | 1,96 | 1,54 |
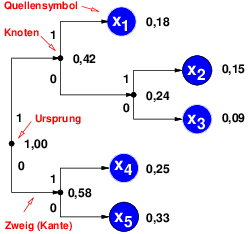
Kodebäume,wie in Abb. 7.1.3, sind Hilfsmittel zur optischen Verdeutlichung von Kodeeigenschaften
| X | p(xi) | c(xi) |
| x1 | 0,18 | 11 |
| x2 | 0,15 | 101 |
| x3 | 0,09 | 100 |
| x4 | 0,25 | 01 |
| x5 | 0,33 | 00 |
- Fano-Bedigung: Kein Kodewort darf das
Präfix (Vorsilbe) eines längeren
Kodewortes sein.
→ Ein Kodewort kann dekodiert werden, sobald das letzte Zeichen empfangen wurde.5
Ein Kode ist dekodierbar, wenn aus einer beliebigen Folge von Kodewörtern die ursprünglichen Zeichen der Quelle wiedergewonnen werden können. Maßnahmen dazu sind:
- Bei einem Präfixkode ist kein Kodewort Anfang eines anderen Kodewortes.
- Bei einem Blockkode hat jedes Kodewort die gleiche Wortlänge.
- Bei einem Kommakode wird ein Kommazeichen zur Trennung der Kodewörter verwendet um eine eindeutig Dekodierbarkeit zu erreichen.6
Der Huffman-Kode mit variabler Wortlänge liefert bei kleinster mittlere Wortlänge einen optimalen Präfixkode. Er ist ohne Kommazeichen eindeutig dekodierbar.
→ Einsatz in der Bildkodierung (JPEG, MPEG) und Kodierung von digitalen Audio-Signalen.
Für die Berechnung der Entropie ist die Kenntnis der Wahrscheinlichkeitsverteilung der Symbole notwendig. Man unterscheidet daher bei der Quellenkodierung 3 Gruppen entsprechend den Wahrscheinlichkeiten (Ernst, 2000, Seite 59):
- statistische Wahrscheinlichkeiten
Die Symbole werden entsprechend ihrer bekannten (statischen) Wahrscheinlichkeiten unterschiedlich langen Kodewörtern zugeordnet.
→ Huffman-Kodierung, Morse-Kodierung
- adaptive Wahrscheinlichkeiten
Die unbekannte Wahrscheinlichkeit der Symbole wird durch eine Häufigkeitsanalyse vor der Kodierung messtechnisch bestimmt.
→ Modifizierte Huffman-Kodierung, Lauflängenkodierung
- dynamische Wahrscheinlichkeiten
Die unbekannte Wahrscheinlichkeit der Symbole wird erst während der Kodierung (dynamisch) erstellt.
- Die Lempel- Ziv-Kodierung (LZW, von Lempel, Ziv und Welch) verwendet ein dynamisches Wörterbuch auf Zeichenfolgen an.
- Bei der Arithmetischen Kodierung7 wird einem Quellwort eine Gleitpunktzahl zugeordnet.